[데이터베이스] 쿼리 프로세싱

parser and translator 작성된 쿼리에 문제가 없는지 검사하고 파싱
relational-algebra expression 파싱된 쿼리를 관계대수 표현으로 변환
#이때 쿼리는 진행순서가 있지만 관계대수는 진행순서를 고려한다.
#이런 차이 때문에 변환과정에서 다르지만 같은 결과가 나오는 여러 관계대수로 변환될 수 있다.
#이렇게 드러난 여러 관계대수 중 cost가 가장 적게 드는 플랜을 선택해 실행한다.
데이터베이스의 비용.
응답시간을 cost로 하면 이상적이지만, 쿼리말고 다양한 요인에 의해 달라질 수 있으므로 측정이 힘들다.
cpu cost는 데이터베이스에는 많은 영향을 주지 않는 편이다. (병렬쿼리는 제외)
disk access가 데이터베이스에 많은 영향을 미친다.
disk cost를 하기 전에...
number of seeks
number of blocks read
number of blocks written
간단하게 하기 위해, 읽는 cost와 쓰는 cost가 같다고 가정, 블록 이동을 number of seeks으로 가정
tT 한 블록을 가져오는데 걸리는 시간
tS 한번 seek 하는 시간
b개의 블록을 가져오기위해 s번 움직여야 하는 경우
b*tT + s*tS
추정한 값보다 다르게 나올 가능성이 있다. (버퍼가 활용될 경우 자주 쓰이는 정보를 버퍼에 저장해 성능향상이 이뤄짐)
따라서 버퍼가 완전히 비어있는 상황을 가정한다.
Selection Operation
A1 알고리즘 (linear search)
순서 상관없이 빠짐없이 읽음.
색인을 허용
selection 조건에 어떤게 와도 수행 가능.
#왜 더 빠른 binary search를 안해?
-seek을 여러번 해야 함
-정렬이 보장되어야 가능함.
어떤 결과를 얻을 때까지 예상되는 평균 cost = (한번 seek하는 시간) + (연속된 블록 b개 읽는 시간)
만약 셀렉션이 키속성을 다룰 때(기본키 등) 예상 cost = (한번 seek하는시간) + (연속된 블록 b개 읽는 시간)/2
JOIN
Nested Loop Join 중첩된 조인

for each tuple tR in R do begin
for each tuple tS in S do begin
test pair (tR, tS) to see if they satisfy the join condition Θ 세타를 만족하는 튜플 쌍
if they do, add tR tS to the result 결과에 추가
end
end모든 경우의 수를 검사하므로, 어떠한 조건에도 사용가능함
최악의 경우, (n= 튜플 개수, b- 블록개수)
메모리가 부족해, 한 블록만 올릴 수 있음을 가정
nR*bS+bR(block transfer) + nR+bR(seek)
메모리가 충분해, 릴레이션 모두가 메모리에 올릴 수 있다면(or 작은 릴레이션을
bR+bS(block trasfer) + 2(seek)
이때 중요한 점은 루프를 돌 때, 어떤 릴레이션을 내부 루프로 할지에 따라 cost가 달라진다!
=>상대적으로 작은 릴레이션을 내부 루프에 설정해야 cost가 적다.
#블록 단위 루프
-블록 단위로 비교함으로써 내부 릴레이션 비교cost를 낮춘다.
Indexed nested loop join
for each tuple tR in r do begin
for each tuple tS in s do begin
test pair(tR,tS) to see if they satisfy the join condition
if they do, add tR,tS to the result
end
end안쪽 루프를 돌 때 인덱스를 활용한다.
bR(tR+tS)+nR*c(하나의 튜플을 셀렉션하는 비용)
인덱스가 있으면 transfer에서 유리. 내부를 풀스캔하는 횟수가 줄어듬
만약 두 릴레이션 모두 인덱스를 가질 경우, 더 작은 릴레이션을 외부 릴레이션으로 설정한다.
Merge join


먼저 조건 속성을 기준으로 sort하고 합치는 형식으로 한다.
이때 순서에 유의해야 한다.
cost는 bR+bS(block transfer) + (bR/buffer)올림+(bS/buffer)올림 (seek) + sort cost
#Hybrid merge join
만약 첫째 릴레이션만 정렬되고 두번째 릴레이션은 인덱스 활용을 한다면?
두번째 릴레이션은 인덱스 주소를 정렬시킨다음에, merge는 튜플값을 찾아와서 진행.
Hash Join
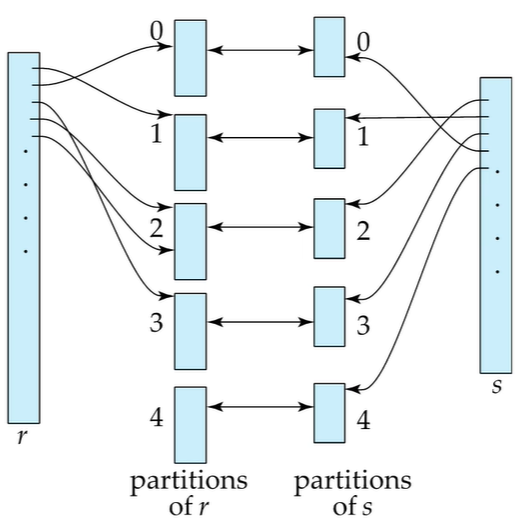
해싱함수 h : 속성 값에 따라 해당 속성을 어디로 매핑되는지 가르켜줌
버킷 n개의 두 릴레이션의 각 속성 값에 따라 나눠서 할당해준다.
똑같은 버킷에 해당된 튜플들의 조인여부를 따진다.
하지만 해싱함수도 완벽하지 않으므로 다른 속성 값을 가진 튜플이 존재할 수 있다.
이럴 경우 해당 버킷에서 다른 해싱함수를 사용해 분리한다.
(이렇게 하고 나서도 똑같은 속성값을 가졌는지 확인해줘야 한다.)
큰 릴레이션(r)을 probe relation이라하고, 작은 릴레이션을 build relation 이라 한다.
버킷 갯수 n은 어떻게 해야하나? #M은 메모리의 블록개수이다.
(bS/M)올림*1.2(f) 이다.
먼저 이상적인 해싱함수에 따른다면, S의 블록 갯수를 버킷 개수로 나눈 것은 메모리보다 작아야 한다.
M>=bS/n 이 수식을 n을 기준으로 다시 쓰면 n>=bS/M이 된다.
이때 f는 현실에선 해싱함수가 이상적이지 않기 때문에 곱해주는 수이다. 대략 1.2로 가정한다.
이때 probe relation(r)은 고려하지 않는다.
hash overflow가 발생할 경우..?
오버플로우는 한 파티션(버킷)에 지나치게 많은 튜플이 담긴 것을 의미한다.
이럴 경우 해당 파티션을 다른 해쉬항수로 다시 나눠줘야 한다.(probe 쪽도 동일하게 적용해줘야 한다.)
만약 같은 값이 많아서 생기는 오버플로우는 nested 루프로 해결해야 한다.(해쉬조인으로는 해결이 힘들다)
해쉬조인 cost
3(bR+bS)올림 +4*n(해쉬함수의 오류를 최악의 상황으로 가정, 굉장히 작은 값) (block transfer) +
2(bR/버퍼)올림+2(bS/버퍼)올림 + 2n(버킷에 나눈 후 해시인덱스를 만들어 비교하는 seek) (seek)
만약 build input이 메모리에 모두 들어가면
bR+bS
#hybrid hash join
build input을 모두 메모리에 넣지는 못하는 애매한 상황
memory가 25 block이고 build input이 100;(20*5)일때
20개(첫 블록)을 build input이 모두 들어갔다고 가정하고 해쉬조인하고 나머지 5개를 일반적인 해쉬조인으로 처리한다.